ZooKeeper 简介及应用
早几年就接触过ZooKeeper,应用不算深入,理解不算透彻,趁着近期略有闲暇,觉得有必要把相关的知识点梳理和总结一下。
ZooKeeper 简介
简单来讲,ZooKeeper 就是一个可扩展的高吞吐分布式协调系统。 基本上通过解答以下几个问题,能大致对 ZooKeeper 做一个快速的了解。
ZooKeeper 是什么?
其前身由yahoo开发(目前已成为Apache的一个顶级项目),用于解决分布式系统中的数据一致性问题,因所有的分布式系统都会面临这一问题,所以在开发hadoop时将这个问题抽象出来,提出了一个独立和通用的解决方案,也就是现在的zookeeper。由于zookeeper具备如下的优势,逐步成为很多知名分布式系统的基础组件,例如:hadoop、kafka、dubbo等。
设计目标
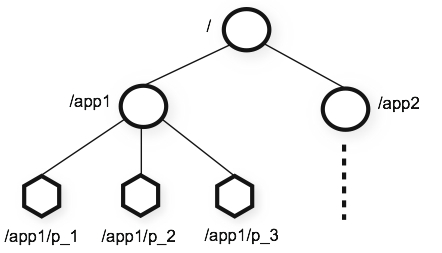
- 类似于标准文件系统,各个进程之间的协调通过共享分级命名空间,目录或者文件被称为
znodes,这些数据都会被保存到zk的实例内存中 - 以集群形式提供服务
- 有序性
- 高性能
- 极简api 一共7个(create、delete、exist、get data、set data、get children、sync)
ZooKeeper 结构
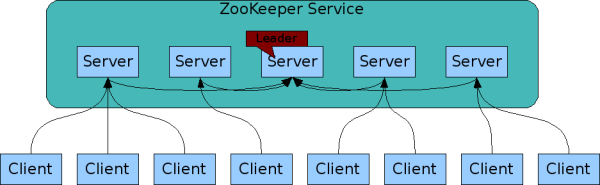
一般来讲,ZooKeeper 服务集群由大于等于3的单数个服务器构成,在每台服务器内存中维护类似于文件系统的树形数据结构,其中的一台作为主控节点,其余作为从属节点。写操作只能由主控节点响应,读可由任务节点响应,如果服务期间主控节点宕机,则其余节点可再选举出新的主控节点。
从这个结构设计来看,主控节点因只有一个,在写操作上天然存在瓶颈,所以更适合读多写少的应用场景。
集群结构
节点模型
ZooKeeper 优势
- 基于watcher的通知回调机制,基于该机制,可实现配置管理的热加载、服务注册和发现等等
- 性能表现优异,能支撑上万客户端的并发操作
- 使用zab作为其一致性协议实现,简单介绍一下,zab协议脱胎于Paxos,后者以难于理解和实现著称,更多是在学术界研究,工程难以实施,而 zab 协议简化了 Paxos 中的二阶段提交,提升了系统性能;利用自增序列,保证了顺序处理逻辑以及更容易的故障恢复实现。
主要应用场景
- 分布式锁
- 服务注册
- 配置管理
- 名称服务
- 分布式锁
- leader选举
Quick Start
系统要求
zookeeper server 端可运行于主流linux发行版和windows之上,软件环境需要依赖jdk,版本大于1.7即可。 如采用集群方式部署,3个节点是最小化要求。
据官方介绍,zk对硬件要求不是很高,2 Core / 2G RAM / 80G 即可。
本文环境信息:
- centos 6.6
- openjdk 1.8
- zookeeper 3.4.8
配置文件
一般位于 ./conf/zoo.cfg,示例如下:
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888几个容易理解错误的配置
- initLimit # The number of ticks that the initial synchronization phase can take
初始连接到 leader 节点的超时时间,具体的 value 指 tickTime 的倍数,如果设置为5,则超时为10秒。
- syncLimit # The number of ticks that can pass between sending a request and getting an acknowledgement
集群中 follower 到 leader 的每次请求超时时间
集群信息配置
server.{no}={host}:{cordinate_port}:{election_port}
- no # 服务器编号
- host # 服务器IP或主机名
- cordinate_port # 主从server之间的通讯端口
- election_port # 选举端口
命令行工具
启动server
./bin/zkServer.sh start四字命令
结合网络工具 nc ,zookeeper 提供了一些四字命令来查询服务器相关信息,例如:
查看该服务器上的统计信息:
echo stat | nc 127.0.0.1 2181输出如下:
Latency min/avg/max: 0/0/4372
Received: 97613067
Sent: 97613133
Connections: 7
Outstanding: 0
Zxid: 0x6000beb9a
Mode: leader
Node count: 150zkCli.sh
zookeeper 提供了一个类 shell 的一个客户端工具 zkCli.sh ,可方便查看服务器信息和进行相关管理操作。
sh ./zkCli.sh -server 127.0.0.1:2181常见问题
如启动失败,会在 ./bin 目录下生成 zookeeper.out 文件,可查询具体出错原因。
缺少myid文件
/var/lib/zookeeper/myid file is missing
到相应目录创建该文件,并编辑该文件的值为当前 server 的序号。